Tương quan Pearson – Stata
Giá trị hệ số xác định R bình phương trong hồi quy tuyến tính giản đơn chính là tham số ước lượng của hệ số tương quan Person. Nội dung bài viết này trình bày về hệ số tương quan Pearson.
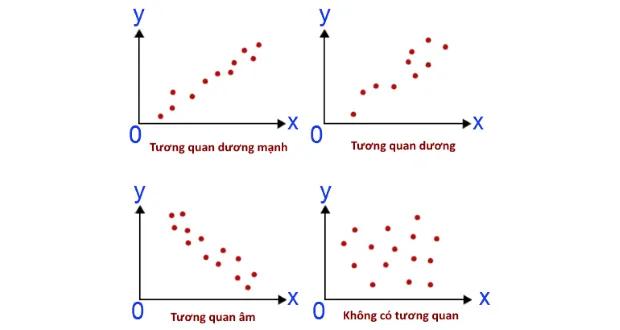
Tương quan (correlation) cho biết mối liên hệ tương đối giữa 2 biến. Hệ số tương quan (correlation coefficient) sẽ cho biết độ mạnh hay mức độ liên hệ giữa 2 biến.
Có 2 phương pháp xác định sự tương quan là:
Xem thêm: Ý nghĩa và cách tính hệ số tương quan Pearson
Ví dụ: chúng ta muốn biết doanh số bán hàng ở một năm có mối quan hệ như thế nào với những năm trước và những năm sau đó. Dữ liệu về doanh số bán hàng từng năm của 25 cửa hàng được tổng hợp ở file dữ liệu thực hành là use https://www.vietlod.com/data/paired-t-test.dta, clear
Thông tin chung về dữ liệu được mô tả bằng như bên dưới:
su DT2011 DT2012 DT2013

Giá trị trung bình về doanh thu của 24 cửa hàng trong 3 năm 2011, 2012, 2013 lần lượt như sau: 893.96; 832.12; 537.63
Trước khi xác định hệ số tương quan Pearson, chúng ta cần kiểm tra dạng phân phối của của các biến liên tục.
Xem thêm: Kiểm tra phân phối chuẩn của biến.
Trong ví dụ này các biến DT2011, DT2012, và DT2013 là những biến không có phân phối chuẩn. Tuy nhiên, nhằm mục đích minh họa cách thực hiện tính hệ số tương quan Pearson trên Stata nên chúng ta xem như biến DT2011 và DT2012 là có phân phối chuẩn.
Khi đó, hệ số tương quan Pearson được tính toán trên Stata bằng câu lệnh corr như sau:
corr DT2011 DT2012

Kết quả cho thấy, với giá trị hệ số tương quan bằng 0.8706 cho thấy một mối tương quan dương mạnh giữa 2 biến DT2011 và DT2012. Tuy nhiên, với câu lệnh corr này thì chúng ta không thể biết được mối tương quan này có ý nghĩa thống kê hay không.
Để biết được mức ý nghĩa thống kê của các hệ số tương quan Pearson, chúng ta có thể sử dụng lệnh pwcorr với tùy chọn star(0.05) để thay thế. Kết quả ở hình trên cho thấy, sự tương quan giữa 2 biến DT2011 và DT2012 là có ý nghĩa thống kê ở mức 5%.
Xem thêm: tương quan hạng Spearman