Xác suất dự đoán hồi quy logit – STATA
Xác suất dự đoán của biến phụ thuộc theo 1 biến liên tục
Tương tự với biến danh mục, chúng ta cũng có thể tính giá trị xác suất dự đoán theo các giá trị của biến liên tục. Phần bên dưới sẽ minh họa mức xác suất học lên cao ứng với 3 giá trị điểm trung bình gpa (2, 3, và 4).
- Nhóm 0: margins, at(gpa=(2/4)) predict(outcome(0)) atmeans

- Nhóm 1: margins, at(gpa=(2/4)) predict(outcome(1)) atmeans

- Nhóm 2: margins, at(gpa=(2/4)) predict(outcome(2)) atmeans

Nhận xét: Tại mỗi giá trị của gpa, giá trị xác suất dự báo cao nhất ở nhóm thấp nhất (không có khả năng) và tăng dần ở các nhóm cao hơn (có khả năng, và rất có khả năng)
3.Xác suất dự đoán của biến phụ thuộc theo sự kết hợp của các biến giải thích
Để hạn chế việc nhập lệnh, chúng ta có thể sử dụng lệnh lặp forvalues để tính toán các giá trị xác suất dự đoán ứng với mỗi giá trị của gpa=3.5, pared=1, và public=1 trong 3 nhóm của biến phụ thuộc như sau:
forvalues i=0/2 {
margins, at(gpa=3.5 pared=1 public=1) predict (outcome(`i’))
}
Tôi xin bỏ qua các kết quả xác suất dự đoán trong câu lệnh lặp trên (kết quả quá dài).
Nhận xét: mặc dù thao tác nhập lệnh được rút ngắn, tuy nhiên, kết quả hiển thị vẫn còn rất dài với nhiều bảng. Điều này khó khăn trong việc so sánh xác suất dự đoán ở từng nhóm. May mắn rằng trong Stata hỗ trợ các công cụ đồ thị rất tốt. Các bạn có thể sử dụng các lệnh đồ thị trong stata để hiển thị các kết quả tính toán ở trên dưới dạng kết hợp.
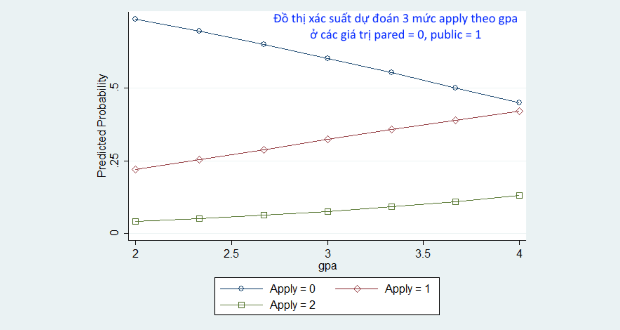
Chẳng hạn, chúng ta có thể so sánh xác suất dự đoán của 3 nhóm trong biến apply theo các giá trị điểm trung bình gpa (từ 2 đến 4) trong trường hợp pared=0 và public=1 như sau:

Hoặc được thể hiện ở dạng xác suất dự đoán cộng dồn như hình:

Rõ ràng nhìn vào đồ thị này, chúng ta có thể dễ dàng phân tích xác suất dự đoán của biến phụ thuộc theo các mức giá trị của biến giải thích. Chẳng hạn, khi pared=0 và public=1 thì xác suất học lên của các sinh viên nhóm 0 (không có khả năng) giảm dần theo sự tăng dần của điểm số gpa. VÀ điều này ngược ở các nhóm 1 và nhóm 2 của biến phụ thuộc.
Đồng thời, đồ thị xác suất dự đoán tích lũy cũng cho thấy khả năng học lên cao của nhóm 2 (rất có khả năng) luôn cao hơn so với nhóm 1 và nhóm 0.
Các bạn cũng có thể thực hiện và giải thích tương tự cho trường hợp pared=1 và public=1 (hình bên dưới) và 2 trường hợp còn lại (pared=0, public=0; pared=1 và public=0):


NHẬN XÉT: Các bạn có thể sử dụng phương pháp tính toán và giải thích kết quả xác suất dự đoán này áp dụng cho các mô hình hồi quy logit nói chung.
Đọc thêm: Hồi quy logit thứ tự trên STATA, SPSS.
e chào thầy! khi em chạy hồi quy logistic STATA thì kết quả có hiện 6.30e-06 làm sao chuyển kết quả này về dạng số ạ?
Bạn thử dùng tùy chọn cformat(%7.4f) phía sau câu lệnh logit .