Kiểm định thống kê
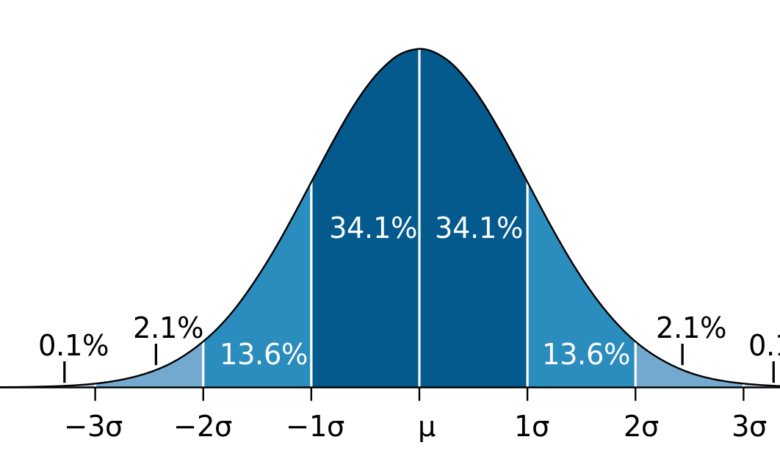
Giới thiệu về kiểm định thống kê
Bài viết này sẽ trình bày các thủ tục kiểm định thống kê thường được sử dụng trong phân tích dữ liệu. Các thủ tục này được trình bày vắn tắt, tập trung chủ yếu vào ý nghĩa chính của thủ tục. Nội dung bài viết được tham khảo từ nhiều nguồn, trong đó quan trọng nhất là IDRE
Dữ liệu thực hành
Các ví dụ minh họa trong site này phần lớn sử dụng bộ dữ liệu vietlod. Bộ dữ liệu gồm 7287 quan sát là người lao động trên cả nước. Các thông tin khảo sát chính bao gồm: giới tính (gender), tuổi (age), dân tộc (ethnic), bằng cấp (degree), nơi sinh sống (region, urban), số năm đi học (school), số năm kinh nghiệm (exp), doanh nghiệp hoạt động (section), lĩnh vực làm việc (structure), thu nhập (earn)…
Bên cạnh đó, một bộ dữ liệu khác cũng được sử dụng đó là bộ dữ liệu hsb2 của IDRE. Đối tượng khảo sát của bộ dữ liệu này là 200 học sinh từ trung học trở xuống. Các biến chính trong bộ dữ liệu bao gồm điểm số các môn toán (math), đọc (read), viết (write), chương trình học (prog), giới tính (female)…
Các phép kiểm định thống kê
Kiểm định t-test về trung bình của mẫu
- Kiểm định t-test về trung bình của mẫu cho phép chúng ta kiểm tra xem liệu trung bình (mean) của một mẫu (của một biến tỉ lệ có phân phối chuẩn) có khác thống kê với một giá trị giả định ban đầu hay không.
- Ví dụ: chúng ta muốn kiểm tra xem thu nhập trung bình của người lao động cả nước năm 2010 tại Việt Nam khác với 2,4 triệu đồng/người/tháng hay không? Chúng ta có thể xem thực hành như sau:
Kiểm định trung vị của mẫu
Kiểm định trung vị của mẫu (one sample median test) cho phép chúng ta kiểm tra xem trung vị (median) của một mẫu có khác ý nghĩa thống kê với một giá trị giả định ban đầu hay không. Điểm khác biệt giữa one sample median test và one sample t-test ở chổ, one sample median test không giả định biến được kiểm định là biến tỉ lệ hoặc có phân phối chuẩn như trường hợp one sample t-test.
Kiểm định khác biệt giữa 2 tỉ lệ
Kiểm định tỉ lệ nhị thức (one sample binomial test) cho phép chúng ta kiểm tra xem tỉ lệ của các giá trị trong biến phân loại 2 mức có khác ý nghĩa thống kê với nhau hay không. Chẳng hạn, xét tỉ lệ người lao động nam và nữ (biến gender) trong bộ dữ liệu khảo sát có bằng nhau hay không. Hay kiểm định giá trị tỉ lệ nam/nữ có bằng 50% hay không.
Độ phù hợp Chi-bình phương
Kiểm định độ phù hợp Chi – bình phương cho phép chúng ta kiểm tra xem tỉ lệ các thành phần trong biến phân loại có khác ý nghĩa thống kê với các tỉ lệ giả định ban đầu hay không. Chẳng hạn, giả sử người ta tin rằng trình độ học vấn của người lao động cả nước là 60% là từ PTTH trở xuống, 30% là trung cấp – cao đẳng và 10% là từ đại học trở lên. Khi đó, trong mẫu dữ liệu thu thập, chúng ta sẽ kiểm tra lại tỉ lệ này có khác ý nghĩa thống kê với những gì mọi người đã nghĩ ban đầu hay không.
Kiểm định giá trị trung bình của 2 mẫu độc lập t-test
Kiểm định giá trị trung bình của 2 mẫu độc lập t-test được sử dụng khi bạn muốn so sánh giá trị trung bình của một biến phụ thuộc dạng khoảng có phân phối chuẩn theo hai nhóm giá trị của một biến độc lập có bằng nhau hay không. Ví dụ, thu nhập trung bình của người lao động nam và người lao động nữ có bằng nhau hay không?
Kiểm định Wilcoxon-Mann-Whitney
- Kiểm định Wilcoxon-Mann-Whitney là một kiểm định phi tham số (non-parametric analog) đối với các mẫu độc lập sử dụng trong t-test và có thể được sử dụng khi chúng ta không giả sử rằng biến phụ thuộc là biến tỉ lệ có phân phối chuẩn (chúng ta chỉ giả định biến phụ thuộc tối thiểu là biến thứ tự).
- Lưu ý rằng, cú pháp lệnh trong SPSS đối với kiểm định Wilcoxon-Mann-Whitney là gần như tương tự với cú pháp trong kiểm định t-test về các mẫu độc lập. Giả sử, kiểm định về thu nhập trung bình của người lao động nam và nữ như ở trường hợp kiểm định t-test, tuy nhiên, chúng ta không giả sử biến phụ thuộc (trong trường hợp này là biến thu nhập earn) không có phân phối chuẩn.
- Kiểm định Chi – bình phương được sử dụng khi chúng ta muốn xem liệu có mối quan hệ giữa hai biến phân loại (categorical variables).
Trong SPSS, tùy chọn kiem-dinh-chi2 sẽ được sử dụng ở tùy chọn thống kê (statistics) trong câu lệnh crosstabs để tính giá trị Chi – bình phương tính toán và giá trị p-value tương ứng. Sử dụng số liệu về khảo sát người lao động để xem xét mối quan hệ giữa giới tính (gender) và loại hình doanh nghiệp (section) mà người lao động làm việc. - Lưu ý rằng, kiểm định chi – bình phương giả định rằng tần suất kì vọng của mỗi ô là từ 5 trở lên. Giả định này sẽ dễ dàng được thỏa mãn trong ví dụ bên dưới. Tuy nhiên, nếu giả định này không được thỏa mãn thì xem thêm kiểm định Fisher’s kiem-dinh-fisher bên dưới.
Kiểm định Fisher’s
Kiểm định Fisher’s kiem-dinh-fisher được sử dụng khi chúng ta muốn thực hiện kiểm định chi – bình phương nhưng một hoặc nhiều ô trong dữ liệu có tần suất (frequency) kì vọng từ 5 trở xuống. Nhắc lại rằng, kiểm định chi – bình phương giả định rằng tần suất kì vọng của mỗi ô là từ 5 trở lên, nhưng kiểm định Fisher’s kiem-dinh-fisher lại không có những giả định như vậy. Kiểm định Fisher’s kiem-dinh-fisher sẽ được sử dụng bất kể tần suất kì vọng là nhỏ như thế nào.
- Kiểm định ANOVA một chiều hay còn gọi là phương pháp phân tích phương sai một chiều (one-way analysis of variance) được sử dụng khi chúng ta có một biến phân loại độc lập (categorical independent variable) và một biến phụ thuộc tỉ lệ có phân phối chuẩn (normally distributed interval dependent variable) và chúng ta muốn kiểm tra xem có sự khác biệt về giá trị trung bình của biến phụ thuộc theo các mức của biến phân loại (biến độc lập) hay không. Chẳng hạn, chúng ta muốn biết thu nhập trung bình của người lao động Việt Nam năm 2010 ở các khu vực (nông nghiệp, công nghiệp, và dịch vụ) có khác nhau hay không.
- Như vậy kiểm định ANOVA một chiều chính là dạng mở rộng của kiểm định t-test. Kiểm định t-test chỉ áp dụng khi so sánh giá trị trung bình của một biến phân loại 2 mức, và trường hợp với biến phân loại từ 2 mức trở lên thì phải áp dụng t-test nhiều lần (Cn,2) hoặc sử dụng kiểm định ANOVA.
- Kiểm định Kruskal Wallis được sử dụng khi chúng ta có một biến độc lập với hai hoặc nhiều mức và một biến phụ thuộc thứ tự (ordinal dependent variable). Đây là một dạng khác, được gọi là kiểm định ANOVA phi tham số (non-parametric version of ANOVA) và là một dạng tổng quát của kỹ thuật kiểm định Mann-Whitney vì nó cho phép thực hiện 2 nhóm trở lên.
- Chúng ta sẽ sử dụng lại trường hợp thu nhập trung bình của người lao động Việt Nam năm 2010 ở các khu vực (nông nghiệp, công nghiệp, và dịch vụ), tuy nhiên chúng ta sẽ không giả sử thu nhập của người lao động có phân phối chuẩn.
Kiểm định t-test cặp đôi
Kiểm định t-test cặp đôi (Paired t-test) được sử dụng khi chúng ta muốn biết liệu giá trị trung bình của biến tỉ lệ (phân phối chuẩn) trong hai nhóm (có liên quan) có khác nhau hay không. Giả sử, chúng ta muốn liệu có sự khác nhau giữa lượng thuốc lá tiêu thụ ở thời điểm trước và sau khi chính phủ tăng thuế tiêu thụ đặc biệt đối với mặt hàng này?
Kiểm định Wilcoxon về dấu của hạng
Kiểm định Wilcoxon về dấu của hạng (The Wilcoxon signed rank sum test) là một dạng kiểm định phi tham số của kiểm định t-test bắt cặp (paired samples t-test). Chúng ta sử dụng Kiểm định Wilcoxon về dấu của hạng khi chúng ta không muốn giả sử sự khác nhau giữa hai biến có dạng khoảng và có phân phối chuẩn (nhưng chúng ta giả sử rằng sự khác nhau đó là có thứ tự). Sử dụng lại số liệu của kiểm định paired sample t-test, nhưng chúng ta không giả sử sự khác nhau giữa số lượng thuốc tiêu thụ trước và sau thời điểm tăng thuế tiêu thụ đặc biệt có phân phối chuẩn.
- Chúng ta sẽ thực hiện kiểm định McNemar nếu chúng ta quan tâm đến kết quả tần số biên của hai biến nhị phân. Kết quả của những biến nhị phân có thể giống với nhau từng cặp hoặc hai biến kết quả của một nhóm riêng rẻ.
- Sử dụng file hsb2, chúng ta tạo thêm hai biến giả (nhị phân) là himath và hiread. Kết quả của hai biến này được xem là một bảng hai chiều ngẫu nhiên (two-way contingency table). Giả thuyết H0 đặt ra là tỷ lệ của sinh viên trong nhóm himath bằng với tỉ lệ sinh viên trong nhóm hiread.
Phương pháp ANOVA lặp 1 chiều
Sử phương pháp ANOVA lặp một chiều khi chúng ta muốn phân tích phương sai cho một biến phân loại độc lập và một biến phụ thuộc dạng khoảng có phân phối chuẩn mà mỗi đối tượng được lặp lại ít nhất hai lần. Điều này tương tự với kiểm định t-test cặp đôi, nhưng cho phép thực hiện với biến phân loại có hai mức trở lên. Kiểm định này sẽ kiểm tra xem liệu giá trị trung bình của biến phụ thuộc có khác theo các mức của biến phân loại không.
- Nếu chúng ta có một biến kết quả dạng nhị phân được lặp lại ở mỗi đối tượng và chúng ta muốn thực hiện một hồi quy logit nhằm tính toán tác động (effect) các lần đo trên mỗi đối tượng, chúng ta có thể thực hiện lặp lại nhiều lần hồi quy logit.
- Trong SPSS, điều này có thể được thực hiện bằng cách sử dụng lệnh GENTLIN và xác định phân phối xác xuất (probability distribution) dạng nhị phân (binomial) và mô hình được sử dụng là logit. Ví dụ, sử dụng file exercise gồm 3 cách đo lường huyết áp (pulse measurements) từ mỗi nhóm gồm 30 người được phân thành 2 nhóm chế độ ăn kiêng khác nhau và 3 nhóm chế độ tập luyện khác nhau. Nếu chúng ta định nghĩa rằng, huyết áp trên 100 là huyết áp cao, chúng ta có thể dự đoán rằng xác suất của huyết cao cao khi áp dụng chế độ ăn kiêng.
- Một ANOVA thừa số (factorial anova) có từ hai biến độc lập dạng danh mục (categorical independent variables) có hoặc không có tương tác với nhau (interactions) và một biến phụ thuộc dạng khoảng có phân phối chuẩn. Chẳng hạn, chúng ta xét thu nhập của người lao động (earn) khác nhau như thế nào theo giới tính (gender) và khu vực sinh sống (urban) bằng cách đánh giá biến thu nhập theo biến tương tác gender*urban.
- Trong SPSS, chúng ta không cần phải lưu trữ thành phần tương tác trong bộ dữ liệu. Chúng ta có thể tạo ra dễ dàng bằng cách nhân (*) hai biến phân loại quan tâm lại với nhau.
Kiểm định Friedman
Chúng ta thực hiện kiểm định Friedman khi chúng ta có các đối tượng trong một biến độc lập với hai hay nhiều mức trở lên và một biến phụ thuộc không phải là dạng khoảng và phân phối chuẩn (nhưng ít nhất là có dạng thứ bậc). Chúng ta sẽ sử dụng kiểm định này để xác định xem có sự khác nhau giữa điểm đọc, viết và điểm toán. Giả thuyết H0 đặt ra trong kiểm định này là phân phối của thứ tự về mỗi điểm số này là giống nhau. Để thực hiện kiểm định Friedman, dữ liệu phải là dữ liệu dài (long format). SPSS sẽ thực hiện điều này bằng cách reshape lại dữ liệu trước khi thực hiện kiểm định.
Hồi quy logistic thứ tự
Ordered logistic regression được sử dụng khi biến phụ thuộc được sắp xếp theo thứ tự (ordered), nhưng không liên tục. Chẳng hạn, trong bộ dữ liệu hsb2 thì biến write3 bao gồm các mức 1, 2, 3 đặc trưng cho các điểm viết thấp, trung bình và cao. Chúng tôi không khuyến khích phân loại các biến liên tục theo cách này, đơn giản chúng tôi tạo ra một biến như vậy để sử dụng minh họa cho ví dụ này. Chúng tôi sẽ sử dụng biến giới tính (female), điểm đọc (read) và điểm xã hội (socst) là các biến giải thích trong mô hình. Sử dụng mô hình hồi quy logit để ước lượng các tham số, tóm tắt kết quả thống kê cùng các các kiểm định giả thuyết.
Hồi quy logit thừa số
Hồi quy logit thừa số (factorial logistic regression) được sử dụng khi chúng ta có hai hay nhiều biến độc lập dạng phân loại nhưng chỉ có một biến phụ thuộc dạng nhị phân (dichotomous dependent). Chẳng hạn, sử dụng số liệu hsb2, chúng ta sẽ sử dụng biến giới tính (female) là biến giả phụ thuộc, bởi vì nó là biến giả (nhị phân) duy nhất trong dữ liệu. Chúng ta sẽ sử dụng biến kiểu chương trình (prog) và kiểu trường học (schtyp) là các biến giải thích.
Sự tương quan
Phân tích tương quan (correlation) sẽ được sử dụng khi chúng ta muốn biết mối quan hệ giữa hai hay nhiều biến dạng khoảng có phân phối chuẩn (normally distributed interval variables). Chẳng hạn, chúng ta muốn tìm hiểu mối tương quan giữa thu nhập (earn) với số năm đi học (school) và số năm kinh nghiệm (exp) của người lao động.
Hồi quy tuyến tính giản đơn
Hồi quy tuyến tính giản đơn cho phép chúng ta muốn biết mối quan hệ tuyến tính giữa một biến giải thích dạng khoảng có phân phối chuẩn (normally distributed interval predictor) và một biến kết quả dạng khoảng phân phối chuẩn (normally distributed interval outcome variable). Chẳng hạn, muốn biết mối quan hệ giữa thu nhập (earn) và số năm đi học (school) của người lao động.
Kiểm định tương quan phi tham số
Kiểm định Spearman về sự tương quan được sử dụng khi một hoặc cả hai biến không được giả sử có dạng khoảng có phân phối chuẩn (giả sử là biến thứ bậc). Trong ví dụ trên, nếu chúng ta không giả sử thu nhập và số năm đi học là các biến khoảng có phân phối chuẩn thì sự tương quan giữa 2 biến này có thể được kiểm chứng bởi kiểm định Spearman.
Hồi quy Logit giản đơn
Hồi quy Logit giả định rằng biến kết quả (outcome variable) là biến nhị phân như có/không, nghèo/không nghèo… Mục tiêu của hồi quy logit là nghiên cứu mối tương quan giữa một hay nhiều biến giải thích và biến kết quả. Chẳng hạn, tìm hiểu về mối quan hệ giữa trình độ học vấn của chủ hộ và tình trạng nghèo của hộ. Các biến giải thích có thể là các biến liên tục, biến nhị phân. Các phương pháp phân tích như hồi qui tuyến tích không phải là một lựa chọn tốt trong trường hợp này vì biến phụ thuộc không phải là biến liên tục mà là biến nhị phân.
Hồi quy đa biến
Hồi quy đa biến là một trường hợp tổng quát của hồi quy tuyến tính giản đơn, khi bao gồm từ hai biến giải thích trở lên. Chẳng hạn, xem xét mối quan hệ giữa thu nhập giữa người lao động theo số năm đi học, số năm kinh nghiệm, khu vực sinh sống…
- Phân tích hiệp phương sai (analysis of covariance) tương tự như phân tích phương sai (ANOVA), ngoại trừ bổ sung thêm biến giải thích có thể là biến danh mục hoặc cũng có thể là biến liên tục.
- Ví dụ, trong phân tích phương sai sử dụng biến điểm viết (write) là biến phụ thuộc, biến chương trình học (prog) là biến giải thích thì trong phân tích hiệp phương sai có thể thêm biến điểm đọc (read) là một biến liên tục với vai trò là biến giải thích trong mô hình.
- Hồi quy logit đa biến tương tự với hồi quy logit giản đơn, ngoại trừ số biến giải thích trong mô hình bao gồm từ 2 biến trở lên. Các biến giải thích có thể là biến khoảng, biến giả nhưng không thể là biến danh mục. Nếu trong mô hình có biến giải thích là biến danh mục thì biến này cần phải được mã hóa thành một hay nhiều biến giả. Số biến giả trong trường hợp này là n – 1, với n là số mức độ trong biến danh mục.
- Ví dụ, chúng ta có một biến danh mục là biến vùng với 6 như ĐB Sông Hồng, BTB và vùng núi phía bắc; BTB và duyên hải miền trug, Tây Nguyên, Đông Nam bộ, ĐB Sông Cửu Long thì chúng ta cần phải mã hóa thành 5 biến giả.
- Phân tích phân tách (Discriminant analysis) là một phương pháp phân tích thống kê được dùng rất nhiều trong Data mining để phân loại các đối tượng (object) vào các nhóm dựa trên việc đo lường các đặc trưng của đối tượng.
- Mục đích chính của phân tích phân tách là: (i) tìm tập hợp những thuộc tính tốt nhất để mô tả đối tượng hay trích lọc thuộc tính (feature extraction) và trích chọn mẫu (sapmple extraction) nhằm làm giảm số chiều biểu diễn đối tượng; (ii) tìm một mô hình tốt nhất để phân lớp các đối tượng.
- Giả sử ta muốn dự báo chương trình học (prog) mà sinh viên sẽ đăng ký dựa vào điểm số các môn toán (math), môn đọc (read), viết (write). Đối tượng ở đây là chương trình học (prog) và các thuộc tính phân lớp là general, academic, và vocation. Các đặc trưng của đối tượng là các biến điểm số như math, read, write.
- Phân tích phân tách được sử dụng khi chúng ta có một hay nhiều biến độc lập dạng khoảng có phân phối chuẩn (gọi là các đặc trưng của đối tượng) và một biến phụ thuộc dạng danh mục (các lớp của đối tượng). Nếu giả định rằng các lớp có thể tách biệt bởi một hàm tuyến tính, chúng ta có thể sử dụng phân tích phân tách tuyến tính (LDA) để xây dựng hàm phân lớp. LDA xây dựng hàm phân lớp dựa trên sự kết hợp tuyến tính giữa các đặc trưng của đối tượng.
Phân tích phương sai đa biến MANOVA
Phân tích phương sai đa biến MANOVA (multivariate analysis of variance) là phương pháp phân tích tương tự như phân tích phương sai ANOVA, ngoại trừ bao gồm 2 hay nhiều biến giải thích trong mô hình. Phân tích phương sai MANOVA một chiều (one-way MANOVA) có một biến độc lập dạng danh mục và 2 hay nhiều biến phụ thuộc. Chẳng hạn, sử dụng file hsb2, chúng ta muốn xem xét sự biến động trong về điểm số đọc (read), viết (write) và điểm toán (math) theo loại chương trình học (prog).
Hồi quy đa biến bội
Hồi quy đa biến bội (Multivariate multiple regression) được sử dụng khi chúng ta có hai hay nhiều biến phụ thuộc được giải thích bởi hai hay nhiều biến độc lập. Ví dụ, chúng ta có thể dự báo điểm số đọc (read) và điểm viết (write) theo các biến giới tính (female), và các điểm số như: toán (math), khoa học (science), xã hội (socst).
Tương quan chính tắc
Tương quan chính tắc (tuong-quan-chinh-tac correlation) là kỹ thuật phân tích đa biến được sử dụng để xem xét mối quan hệ giữa hai nhóm của các biến. Đối với mỗi tập hợp biến, nó tạo ra các biến ẩn (latent variables) và xem xét mối quan hệ giữa các biến ẩn này. Giả sử rằng tất cả các biến trong mô hình là biến dạng khoảng và có phân phối chuẩn. SPSS yêu cầu hai nhóm biến sẽ được phân tách nhau với từ khóa “with” ở giữa, chẳng hạn “manova read write with math science”. Lưu ý, số biến trong mỗi nhóm trước và sau từ khóa “with” không nhất thiết phải bằng nhau.
- Phân tích nhân tố là một dạng của phân tích đa biến, được sử dụng để giảm bớt số biến trong mô hình hoặc phát hiện mối quan hệ giữa các biến. Tất cả các biến liên quan trong phân tích nhân tố cần thiết có dạng khoảng và được giả định có phân phối chuẩn.
- Mục đích của phương pháp là tìm ra các tập hợp (gọi là các nhân tố) ít hơn được rút ra từ một tập hợp nhiều biến quan sát phụ thuộc lẫn nhau nhưng vẫn chứa đựng hầu hết thông tin của tập biến ban đầu (Hair và cộng sự, 1998).
Hệ số tin cậy Cronbach’s anpha
- Hệ số tin cậy Cronbach anpha là một cách đo của sự tin cậy cục bộ (a measure of internal consistency), có nghĩa là nó sẽ liên quan mật thiết với một tập hợp các quan sát trong mỗi nhóm. Nó đôi khi được gọi là số đo mức độ tin cậy của thang đo. Giá trị anpha càng cao không có ngụ ý rằng phép đo là nhất quán (measure is unidimensional).
- Hơn nữa, nếu đo lường độ tin cậy nội tại, chúng ta muốn cung cấp bằng chứng rằng thang đo trong câu hỏi là thống nhất (unidimensional) thì cần phải thực thêm các phân tích khác. Phân tích nhân tố khám phá (Exploratory factor analysis) là một trong những phương pháp kiểm tra tính nhất quán như vậy.
- Nói theo ngôn ngữ kỹ thuật, Cronbach’s alpha không phải là một kiểm định thống kê, nó chỉ là một hệ số của sự tin cậy (coefficient of reliability or consistency).