Hồi quy logit lặp – Stata
3. Link
Chọn dạng liên kết giữa các biến giải thích bới biến phụ thuộc trong mô hình, tùy thuộc vào dạng hàm của biến phụ thuộc. Theo đó, để xác định giá trị của link cần trả lời câu hỏi “dạng hàm của biến phụ thuộc nào được sử dụng để thể hiện mối quan hệ tuyến tính của các biến phụ thuộc (thông qua giá trị trung bình hay giá trị logit)?”
Link
- identity (model mean directly) mặc định cho phân phối Gaussian (normal)
- log mặc định cho phân phối Poisson
- logit mặc định cho phân phối binomial
- power
- probit
4. Correlation structure
Cần lựa chọn Correlation structure (cấu trúc tương quan) nào được xác định trong mô hình ước lượng? Stata hỗ trợ công cụ phân tích 4 loại cấu trúc tương quan phổ biến sau:
- independent
- exchangeable mặc định
- ar #
- unstructured
Kết quả ước lượng phụ thuộc nhiều vào loại cấu trúc tương quan được xác định. Các cấu trúc tương quan khác nhau sẽ có những kết quả ước lượng khác nhau. Do vậy, việc xác định một cấu trúc tương quan phù hợp nhất với dữ liệu là điều rất quan trọng trong phân tích hồi quy logit lặp nói riêng và lệnh xtgee nói chung. Các bạn có thể đọc thêm ở các chuyên đề nâng cao về vấn đề này.
5. Biến nào là biến phân nhóm (clustered) dữ liệu?
Biến phân nhóm theo đối tượng hoặc thời gian được xác định bằng câu lệnh xtset hoặc tiền tố i. hoặc tiền tố t. trong phần tùy chọn của câu lệnh xtgee.
Chúng ta đã biết, bên cạnh các vấn đề về tuổi tác, yếu tố di truyền thì bệnh cao huyết áp (đại diện bởi chỉ số huyết áp) có quan hệ mật thiết với chế độ ăn uống và vận động thể thao hàng ngày. Một nghiên cứu thực nghiệm được thực hiện trên 30 đối tượng tình nguyện để xác định mối quan hệ này. Mỗi đối tượng sẽ yêu cầu thực hiện lần lượt chế độ ăn kiêng, và các chế độ tập luyện (1, 2, 3). Trước và sau mỗi giai đoạn nhóm nghiên cứu sẽ tiến hành ghi nhận chỉ số huyết áp ở từng đối tượng. Kết quả được thể hiện ở file dữ liệu thực hành repeated-logit.dta
Trong ví dụ này, chúng ta muốn biết ảnh hưởng của chế độ ăn kiêng và chế độ luyện tập lên bệnh cao huyết áp cũng như là xác suất bị cao huyết áp ở nhóm chế độ này. Sử dụng số liệu trên với giả định rằng chỉ số huyết áp trên 100 được xem là bị cao huyết áp.
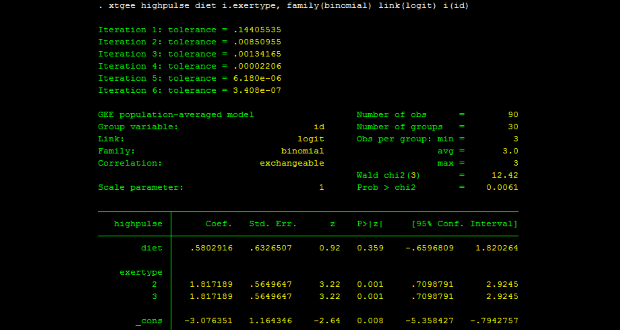
Trong trường hợp này này biến phụ thuộc có dạng phân phối là binomial, do vậy chọn family(binomial). Đồng thời sự liên kết giữa biến phụ thuộc với các biến độc lập được thể hiện tuyến tính qua hàm logit, vì vậy chọn link(logit). Biến phân nhóm để xác định các đối tượng là id, do vậy thiết lập i(id), (không có chuỗi thời gian nên không cần xác định tiền tố t.). Một vấn đề rất quan trọng khác là xác định cấu trúc tương quan phù hợp nhất với dữ liệu. Ở đây, chúng ta chọn cấu trúc mặc định là exchangeable, tuy nhiên, để kết quả phân tích đạt được độ tin cậy cao, cũng như có sức mạnh giải thích thì chúng ta cần kiểm tra lại cấu trúc tương quan này.
Kết quả phân tích hồi quy logit lặp cho ví dụ trên bằng câu lệnh xtgee như sau:
xtgee highpulse diet i.exertype, family(binomial) link(logit) i(id)

Kết quả cho biến diet không có ý nghĩa thống kê ở mức 5%. Điều đó có nghĩa chưa có bằng chứng cho thấy chế độ ăn kiêng tác động đến bệnh cao huyết áp. Trong khi đó, các chế độ tập luyện khác nhau thì ảnh hưởng khác nhau đến bệnh cao huyết áp.
Đồ thị minh họa xác suất biên của khả năng bị cao huyết áp theo 3 chế độ tập luyện trong hồi quy logit lặp được thể hiện như hình bên dưới:

Ở hình trên, đường xác suất khả năng bị cao huyết áp ở nhóm luyện tập 2 và 3 là trùng nhau, bởi xác suất biên theo các nhóm này là trùng nhau, được thể hiện ở bảng:

Đọc thêm: hồi quy logit lặp trên SPSS