KTL nâng cao
Khắc phục corrected error trong dữ liệu đa cấp
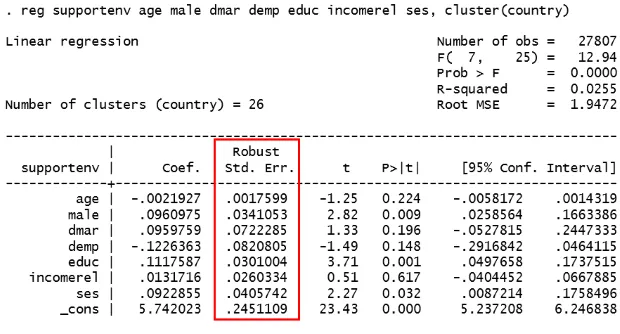
Dữ liệu đa cấp – multilevel data có thể được ước lượng bằng mô hình OLS. Tuy nhiên, việc gom nhóm dữ liệu dẫn đến các vấn đề về sai số tương quan (corrected error), từ đó dẫn đến việc ước lượng giả tạo các sai số chuẩn nhỏ (Sai lầm loại I). Để khắc phục vấn đề này, chúng ta cần kiểm soát được các nguồn gốc gây ra corrected error, và đưa chúng vào mô hình ước lượng. Tuy nhiên, chúng ta không thể nhận diện hoặc đo lường tất cả các cội nguồn gây ra correlated error này. Trong trường hợp này, chúng ta áp …