Kiểm định Friedman – Stata
Tuy nhiên, điều này không đồng nhất với các kiểm định bằng lệnh swilk, sfrancia và sktest như bên dưới.

Đa phần các kết quả kiểm định này đều có mức ý nghĩa trên 10%, do vậy, không có đủ bằng chứng để bác bỏ giả thuyết các biến none, discount, gift có phân phối chuẩn. Kết quả này trái ngược với kết quả kiểm định Kolmogorov – Smirnov (K-S) hoặc Shapiro – Wilk (S-W) trên SPSS ở bài kiểm định Friedman trên SPSS.
Xem thêm: kiểm tra phân phối chuẩn trên SPSS, STATA
Tuy nhiên, 2 phương pháp đồ thị và kiểm định thống kê chưa có một kết quả thống nhất. Do vậy, kiểm định ANOVA lặp 1 chiều không phải là một lựa chọn sử dụng phù hợp. Ngoài ra, bài viết này chỉ nhằm mục đích minh họa việc thực hiện kiểm định Friedman trên Stata nên xem như các biến trên vi phạm giả định về tính phân phối chuẩn. Kiểm định Friedman trên Stata được thực hiện bằng lệnh friedman.
Lưu ý, đây là một công cụ không có sẳn trong Stata, các bạn sử dụng lệnh findit friedman để thêm lệnh vào chương trình.
Trước khi sử dụng lệnh friedman, các bạn cần chuyển đổi dữ liệu dòng (quan sát) thành cột (biến) bằng lệnh xpose với tùy chọn replace như sau:
xpose, clear
Câu lệnh này sẽ tạo ra 25 biến, kí hiệu từ v1 đến v25 chính là 25 quan sát ban đầu được đo lường bởi 3 dòng chính là 3 biến none, discount và gift ban đầu.
Tiếp đến thực hiện kiểm định Friedman bằng cách sử dụng lệnh friedman cho 25 biến v1 – v25 như sau:
friedman v1 – v25
Friedman = 6.3200
Kendall = 0.1264
P-value = 0.0424
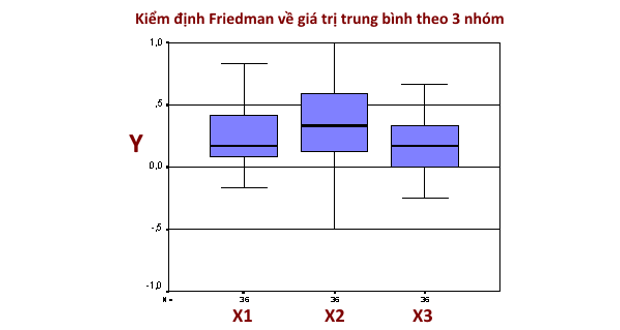
Giá trị thống kê chi2 của kiểm định Friedman bằng 6.32 và giá trị p-value bằng 0.0424 cho thấy có sự khác nhau về doanh thu của các cửa hàng trong 3 năm 2011, 2012, 2013 (mức ý nghĩa thống kê 5%). Kết luận này cũng phù hợp và thống nhất với kết luận khi thực hiện kiểm định Friedman trên phần mềm SPSS.
Sử dụng kiểm định Friedman chúng ta có thể kiểm định sự khác nhau về hiệu quả giữa các chương trình. Trong trường hợp chấp nhận giả thuyết, chúng ta không thể bàn luận gì thêm. Tuy nhiên, trong trường hợp bác bỏ, nếu chỉ dừng ở đây để kết luận rằng có sự khác nhau về hiệu quả giữa các chương trình thì chúng ta không kiểm chứng được chương trình nào sẽ mang lại doanh số bán hàng cao hơn. Trong trường hợp này, để đánh giá so sánh hiệu quả của từng chương trình chúng ta sẽ sử dụng kiểm định dấu hạng Wilcoxon. Để chuyển dữ liệu về dạng ban đầu, chúng ta thực hiện lại lệnh xpose, clear như trên.
Bàn luận về kiểm định Friedman